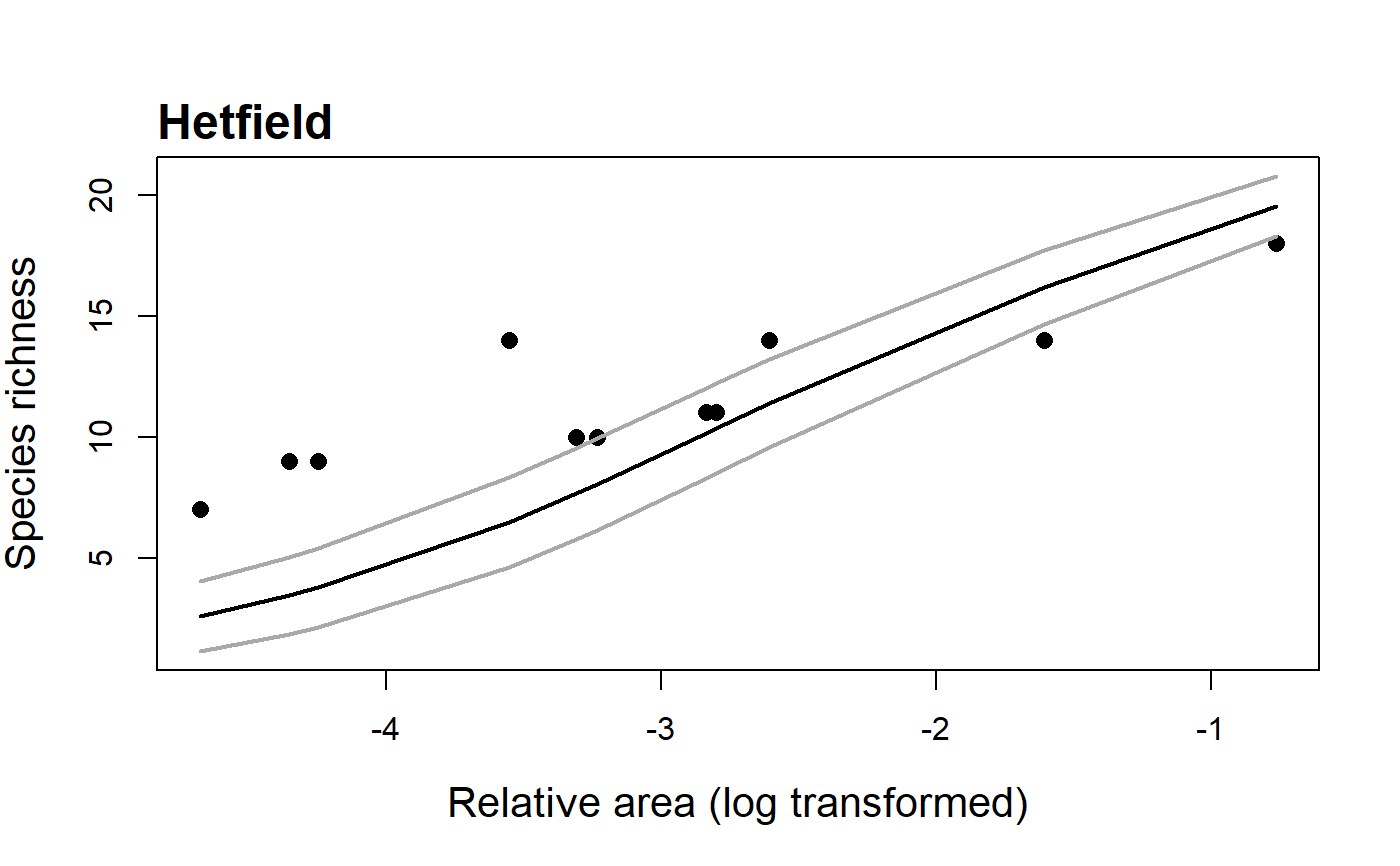
Fit Coleman's (1981) random placement model to a species-site
abundance matrix: rows are species and columns are sites. Note that the
data must be abundance data and not presence-absence data. According to
this model, the number of species occurring on an island depends on the
relative area of the island and the regional relative species
abundances. The fit of the random placement model can be determined
through use of a diagnostic plot (see plot.coleman) of
island area (log transformed) against species richness, alongside the
model’s predicted values (see Wang et al., 2010). Following Wang et al.
(2010), the model is rejected if more than a third of the observed data
points fall beyond one standard deviation from the expected curve.
coleman(data, area)
Arguments
| data | A dataframe or matrix in which rows are species and columns are sites. Each element/value in the matrix is the abundance of a given species in a given site. |
|---|---|
| area | A vector of site (island) area values. The order of the vector
must match the order of the columns in |
Value
A list of class "coleman" with four elements. The first element
contains the fitted values of the model. The second element contains the
standard deviations of the fitted values, and the third and fourth
contain the relative island areas and observed richness values,
respectively. plot.coleman plots the model.
References
Coleman, B. D. (1981). On random placement and species-area relations. Mathematical Biosciences, 54, 191-215.
Matthews, T. J., Cottee-Jones, H. E. W., & Whittaker, R. J. (2015). Quantifying and interpreting nestedness in habitat islands: a synthetic analysis of multiple datasets. Diversity and Distributions, 21, 392-404.
Wang, Y., Bao, Y., Yu, M., Xu, G., & Ding, P. (2010). Nestedness for different reasons: the distributions of birds, lizards and small mammals on islands of an inundated lake. Diversity and Distributions, 16, 862-873.